
One of the quieter benefits of continuous security monitoring is that it catches things you weren’t looking for. You set up detections for one set of threats, and it finds something else entirely. Something that should have been addressed long ago.
Introduction
This is the story of a sustained brute force campaign against a client server, how it was detected, what the investigation uncovered, and why the most valuable finding wasn’t the attack itself, but rather what was revealed about the server’s attack surface.
All client-identifying information has been redacted. The attacker infrastructure, tooling, and remediation steps are documented as they occurred.
Detection
Wazuh, an open source XDR and SIEM solution, flagged an unusual spike in authentication failure events on a monitored client server. Specifically, this was targeting the ProFTPD service. This wasn’t just a single alert, but rather a sustained, high-volume pattern that stood out immediately when looking at the event timeline. A case was opened in IRIS, an open source incident response platform, for tracking and investigation.
The initial alert data pointed to a single source IP hammering FTP authentication. The volume was too consistent and too sustained to be noise, this was immediately classified as an active campaign.
Investigation
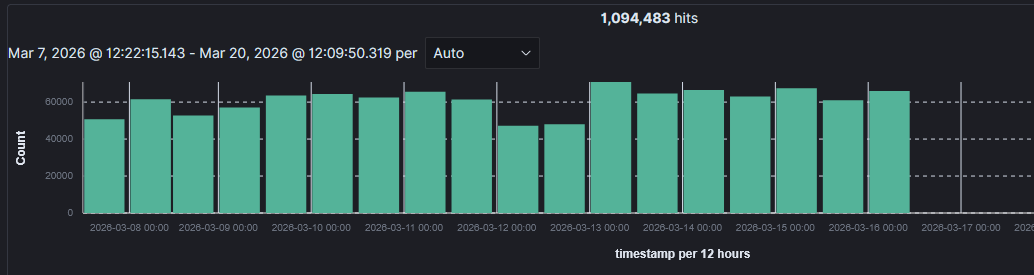
Querying the Wazuh index for the source IP across the full available window showed the timing perfectly. No activity from that IP address prior to March 6, and was sustained until March 16. The campaign ending was unexplained. The attacker IP was still live, and still active against other targets, simply stopped hitting the monitored server.
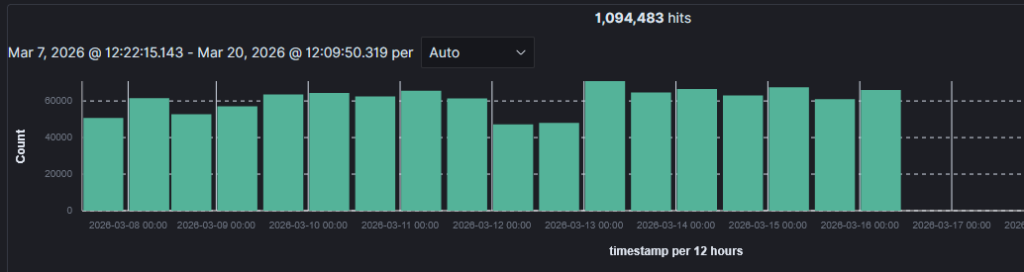
By the end of the campaign, the confirmed attack volume was 502,781 connection attempts.
The source IP resolved to a DigitalOcean Frankfurt droplet, AS14061. A check against AbuseIPDB confirmed that the IP had been reported by other targets for SSH brute force activity as recently as the day the campaign ended. This suggested that the attacker was simply tool cycling through target lists rather than focusing on just one target specifically.
The existing fail2ban configuration was banning offending IPs as expected, but with a bantime of only one hour. Given the campaign duration and volume, this was effectively useless, as the attack would resume as soon as the ban ended.
The Known Unknown: A Service That Outlived Its Purpose
While investigating the campaign, a closer look at the server’s running services produced a finding that was less of a surprise and more of a long-overdue reckoning.
ProFTPD was listening on two ports, 21 and 2222. This wasn’t an unknown service, it was there intentionally from the beginning. The server’s primary administrators are less technical in nature, and SSH key-based authentication and SFTP weren’t realistic options for the initial website transfers. GUI-based file transfers via FTPS were the solution for their workflows, and ProFTPD served that purpose. A classic case of security ideal meeting operational reality. Sometimes you accept the risk when a slightly less secure option is the right one for the client in front of you.
The problem wasn’t that ProFTPD was running. The problem was that it was still running.
The transfer logs were checked as part of the investigation into the open ports, and we saw that the last legitimate FTP use was 18 months prior. The administrators’ workflow had shifted entirely to utilizing the Webmin hosting panel for transferring, and there was no longer a need for ProFTPD. However, no one had gone back to close the door.
This isn’t a problem of “I didn’t know this was running.” This is arguably a more common one affecting self-hosted servers all the way up to corporate environments: a service installed for a specific need still running after that need had passed. The original decision was reasonable, the failure was in not revisiting it.
Remediation
Remediation was straightforward once the picture was clear. The client was notified that FTP had not been used in 18 months and that no active FTP users were configured. Confirmation was obtained before making changes, and then the ProFTPD service was disabled entirely on the server.
Firewall level blocks closed ports 21 and 2222.
Fail2ban was restructured: Ban time was changed from 1 hour to 1 week, with incremental banning enabled for repeat offenders. A sustained campaign like this can cycle through bans, so longer initial bans with escalation means the attack will exhaust itself before it’s ever unbanned.
ASN-level blocking was implemented via nftables. In the course of combing through the logs of this attack, several multi-IP attempts were identified. The ASNs behind these all had malicious indications, and these ASNs were blocked directly in nftables.
SSH hardening implemented. While SSH was not a prime target in this attack, precautions were taken on this service as well. Namely, key-based authentication was enforced, meaning only a valid keypair could connect, password authentication was disabled entirely.
Takeaways
Audit why services are running, not just whether they are. A regular review of listening ports against what you actually need takes minutes and closes attack surfaces you may not know exist.
High-volume brute force against unused services is common and noisy. This campaign generated over 500,000 events against a service with zero legitimate users. Without continuous monitoring, this goes unnoticed until something worse happens. With it, you get an early look at what the Internet thinks is worth attacking on your servers.
Short ban windows don’t stop sustained campaigns. A one-hour bantime is appropriate for incidental probing. Against an automated campaign running for ten days straight, it’s close to useless. Tune bantime to the threat model, not the default.
The campaign revealed more than it achieved. The attacker got nothing, there was no successful authentication, no access to servers. But the investigation it triggered surfaced an 18-month-old attack surface that should have been cleaned up long before any attacker found it. Sometimes, the value of an incident isn’t in stopping the attack, but rather what you learn about your own tech stack while investigating it.